Conceitos de Alto Nível
Esta documentação foi traduzida automaticamente e pode conter erros. Não hesite em abrir um Pull Request para sugerir alterações.
LlamaIndex.TS ajuda você a construir aplicativos com LLM (por exemplo, Q&A, chatbot) sobre dados personalizados.
Neste guia de conceitos de alto nível, você aprenderá:
- como um LLM pode responder perguntas usando seus próprios dados.
- conceitos-chave e módulos em LlamaIndex.TS para compor sua própria sequência de consulta.
Responder Perguntas em Seus Dados
LlamaIndex utiliza um método de duas etapas ao usar um LLM com seus dados:
- etapa de indexação: preparando uma base de conhecimento, e
- etapa de consulta: recuperando o contexto relevante do conhecimento para ajudar o LLM a responder a uma pergunta.
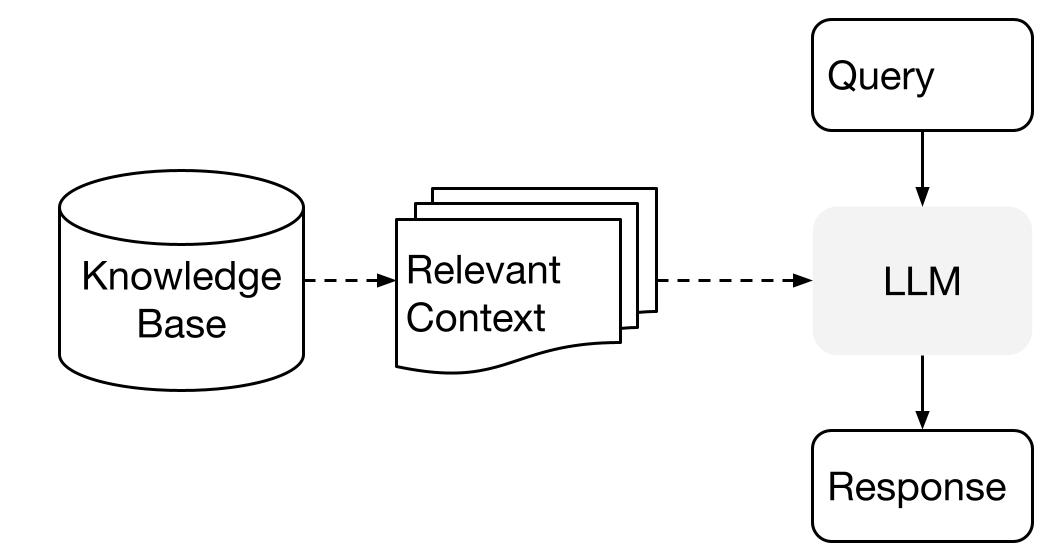
Esse processo também é conhecido como Geração Aprimorada por Recuperação (RAG).
LlamaIndex.TS fornece o conjunto de ferramentas essenciais para tornar ambas as etapas super fáceis.
Vamos explorar cada etapa em detalhes.
Etapa de Indexação
LlamaIndex.TS ajuda você a preparar a base de conhecimento com uma série de conectores de dados e índices.

Carregadores de Dados:
Um conector de dados (ou seja, Reader) ingere dados de diferentes fontes e formatos de dados em uma representação simples de Documento (texto e metadados simples).
Documentos / Nós: Um Documento é um contêiner genérico para qualquer fonte de dados - por exemplo, um PDF, uma saída de API ou dados recuperados de um banco de dados. Um Nó é a unidade atômica de dados no LlamaIndex e representa um "pedaço" de um Documento de origem. É uma representação rica que inclui metadados e relacionamentos (com outros nós) para permitir operações de recuperação precisas e expressivas.
Índices de Dados: Depois de ingerir seus dados, o LlamaIndex ajuda você a indexar os dados em um formato fácil de recuperar.
Por baixo dos panos, o LlamaIndex analisa os documentos brutos em representações intermediárias, calcula incorporações vetoriais e armazena seus dados na memória ou em disco.
Etapa de Consulta
Na etapa de consulta, a sequência de consulta recupera o contexto mais relevante dado uma consulta do usuário, e passa isso para o LLM (juntamente com a consulta) para sintetizar uma resposta.
Isso fornece ao LLM um conhecimento atualizado que não está em seus dados de treinamento originais, (também reduzindo a alucinação).
O desafio chave na etapa de consulta é a recuperação, orquestração e raciocínio sobre bases de conhecimento (potencialmente muitas).
LlamaIndex fornece módulos componíveis que ajudam você a construir e integrar sequências de consulta RAG para Q&A (motor de consulta), chatbot (motor de chat) ou como parte de um agente.
Esses blocos de construção podem ser personalizados para refletir preferências de classificação, bem como compostos para raciocinar sobre várias bases de conhecimento de maneira estruturada.
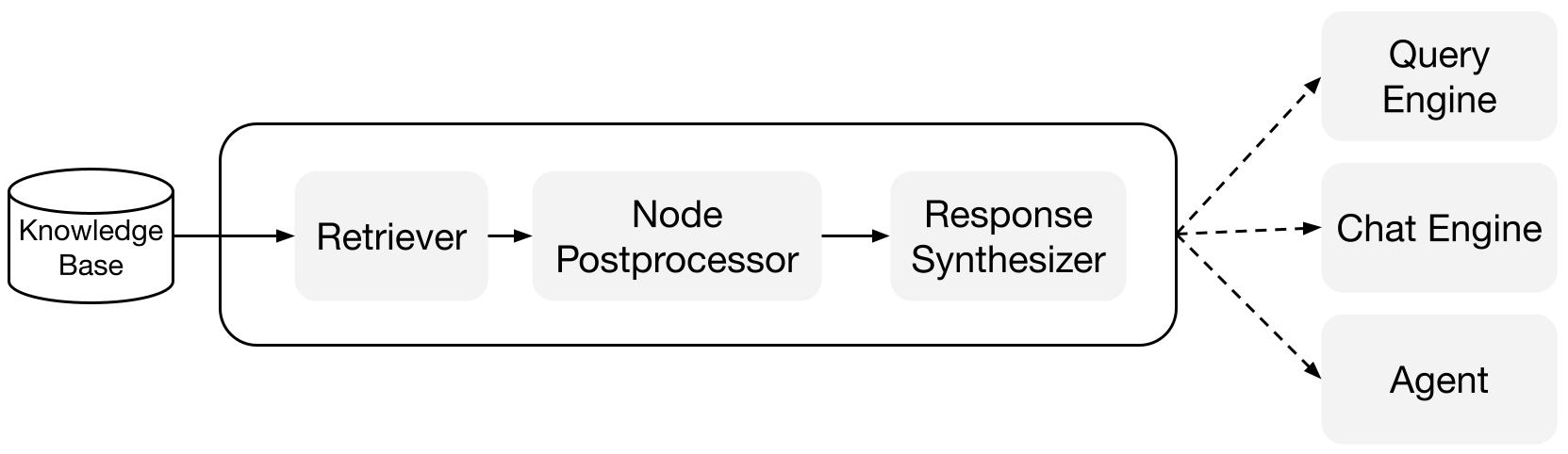
Blocos de Construção
Recuperadores: Um recuperador define como recuperar eficientemente o contexto relevante de uma base de conhecimento (ou seja, índice) quando fornecida uma consulta. A lógica específica de recuperação difere para diferentes índices, sendo a mais popular a recuperação densa em relação a um índice vetorial.
Sintetizadores de Resposta: Um sintetizador de resposta gera uma resposta a partir de um LLM, usando uma consulta do usuário e um conjunto dado de trechos de texto recuperados.
"
Sequências de Consulta
Motores de Consulta: Um motor de consulta é uma sequência de ponta a ponta que permite fazer perguntas sobre seus dados. Ele recebe uma consulta em linguagem natural e retorna uma resposta, juntamente com o contexto de referência recuperado e passado para o LLM.
Motores de Chat: Um motor de chat é uma sequência de ponta a ponta para ter uma conversa com seus dados (múltiplas idas e vindas em vez de uma única pergunta e resposta).
"